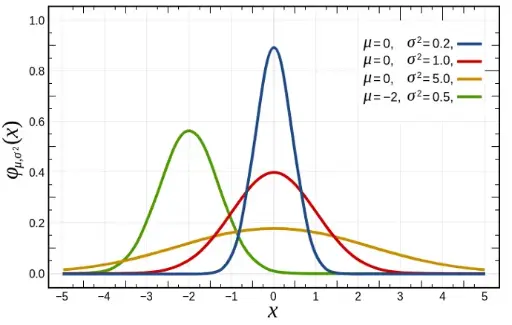
Measures of dispersion and location are crucial for understanding the spread and positioning of data within a dataset. Measures of dispersion provide insights into the variability or spread of the data, helping to assess how much the values differ from the central tendency. Common measures include the range, which is the difference between the maximum and minimum values; the variance, which quantifies the average squared deviation from the mean; and the standard deviation, which is the square root of the variance and represents average deviation from the mean in the same units as the data. Additionally, the interquartile range (IQR) measures the spread of the middle 50% of the data by subtracting the first quartile from the third quartile, providing a robust measure of variability.
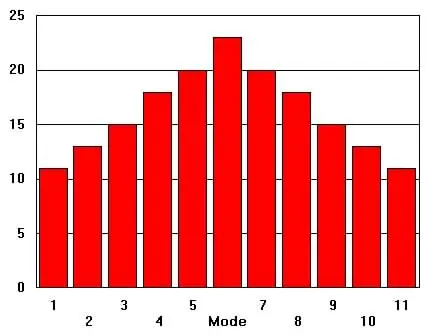
Measures of location focus on identifying the central point or specific positions within a dataset. The mean (arithmetic average) provides a measure of the central value, while the median indicates the middle value when data is ordered. The mode identifies the most frequently occurring value. These measures help in understanding the central tendency and comparing different datasets. Together, measures of dispersion and location offer a comprehensive view of the data's distribution, aiding in effective data analysis and interpretation.